
Addressing Imbalance in Datasets: SMOTE
An imbalanced dataset refers to a scenario in which the distribution of classes within the dataset is significantly uneven. In the context of classification problems, this imbalance arises when the number of instances or samples belonging to one class substantially outweighs the number of instances in another class or classes. The majority class overwhelms the minority class which is relatively a small proportion of the dataset.
Consider an example from the Corporate Credit Rating Prediction Project . As seen from the figure below, certain ratings like ‘Highest Risk’ or ‘Low Risk’ are underrepresented.
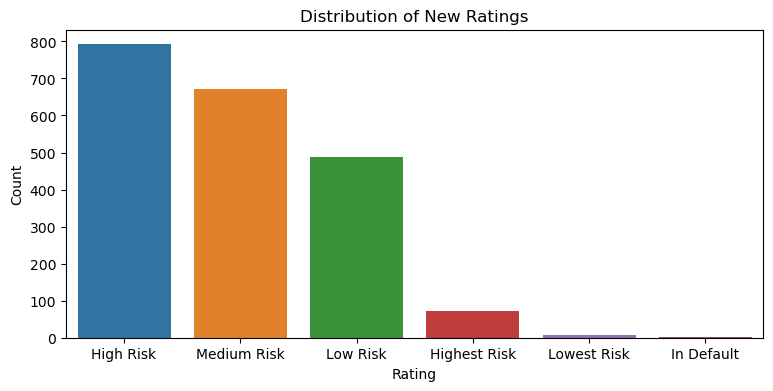
The class imbalance can have notable implications for machine learning models. Traditional algorithms, when trained on imbalanced data, may exhibit biases toward the majority class, leading to suboptimal performance in predicting or classifying instances from the minority class. Consequently, accurate identification and prediction of minority class instances become challenging, and the model’s performance may be skewed towards the majority class. Addressing the challenges posed by imbalanced datasets is crucial in scenarios where both classes are of equal importance, such as in fraud detection, medical diagnosis, or credit rating prediction.
Oversampling and undersampling are two techniques employed to address the issue of class imbalance in datasets.
-
Oversampling: Oversampling involves increasing the number of instances in the minority class by generating synthetic samples or replicating existing instances. The goal is to balance the class distribution, allowing the machine learning model to train on a more equitable representation of both the majority and minority classes.
Oversampling can enhance the model’s ability to capture patterns in the minority class, leading to improved performance on minority class predictions. On the other hand may introduce noise if not applied carefully, and it could potentially lead to overfitting if the synthetic instances are not representative.
-
Undersampling: Undersampling involves reducing the number of instances in the majority class by randomly removing samples or using more sophisticated methods to select a subset of instances. The objective is to balance the class distribution by reducing the dominance of the majority class, allowing the model to focus more on the minority class.
Undersampling reduces the potential for the model to be biased toward the majority class, and it can lead to faster training times with a smaller dataset. One must also pay attention that undersampling may discard potentially valuable information from the majority class, and it could lead to information loss.
The choice between oversampling and undersampling depends on the specific characteristics of the dataset and the problem at hand.
Synthetic Minority Over-sampling Technique (SMOTE) is an oversampling technique proposed by Chawla et al. (2002). This technique generates new minority class samples synthetically. This synthetic generation of minority class has created new samples in the vicinity of existing minority samples using k-NN (k Nearest Neighbor). More specifically, each minority sample is taken for the generation of new samples. However, the k-NN are chosen randomly along the line joining any of the k nearest minority samples for the creation of new balanced dataset. This is clearly demonstarted in the figure below.
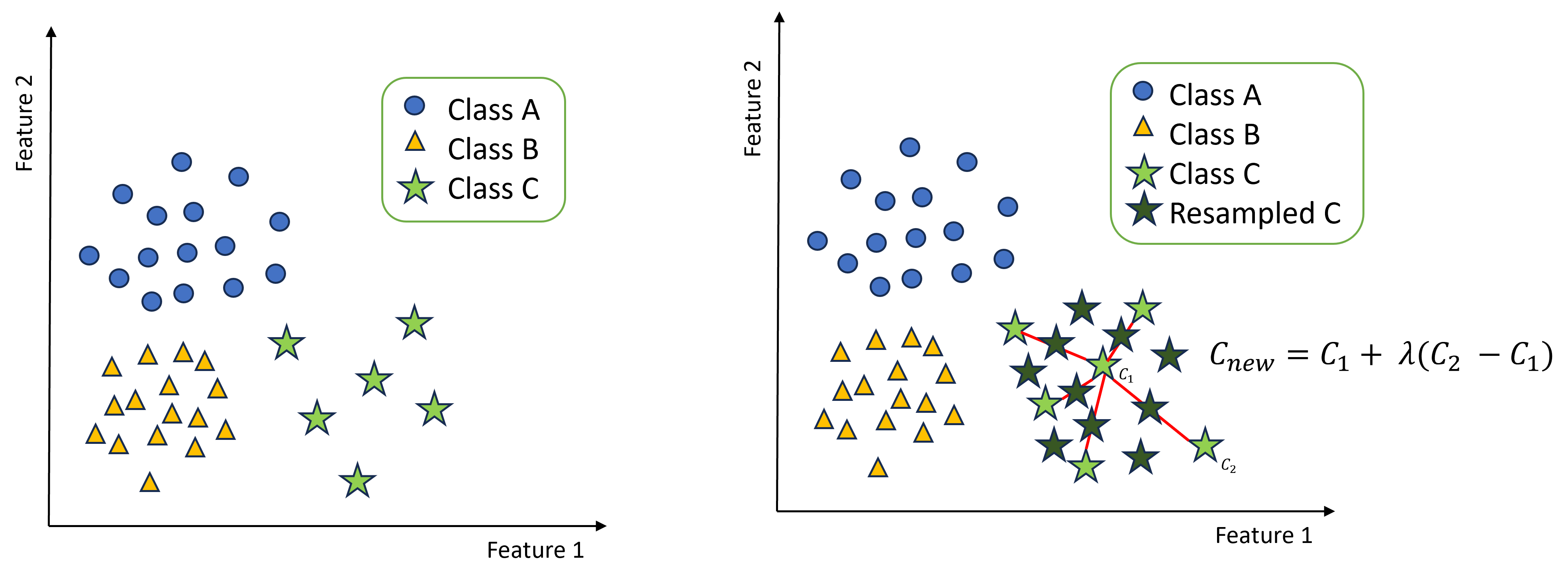
We have 3 classes in the dataset: Class A and Class B are the majority classes and they seem to be almost equal in number. Class C is the minority class that is underrepresented and we have an imbalanced dataset.
Consider a minority class instance $C_{1}$. SMOTE randomly selects another minority class instance $C_{2}$ and generates a synthetic instance $C_{new}$ using the formula:
\[C_{new} = C_{1} + \lambda (C_{2} - C_{1})\]Here, $ \lambda $ is a random number between 0 and 1, determining the position of the synthetic instance along the line connecting $C_{1}$ and $C_{2}$. This process is repeated until the desired balance is achieved.
Python Code:
Implementing SMOTE in Python involves using the imbalanced-learn library. Let X_train and y_train denote the feature matrix and target variable, the code snippet looks like this:
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
# Split your data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2996)
# Apply SMOTE to the training data
smote = SMOTE(sampling_strategy='auto', random_state=2996)
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
Now, X_train_resampled and y_train_resampled contain the oversampled data, ready to be used in training your machine learning model.
In conclusion, SMOTE is a valuable tool for handling imbalanced datasets, ensuring a fair representation of all classes and helps in improving the overall performance and fairness of machine learning models.
References
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321–357. doi: https://arxiv.org/abs/1106.1813